
Perché ora?

Allo stato attuale della tecnologia possiamo addestrare la rete neurale profonda (DNN) per compiti specifici come il rilevamento e il riconoscimento di oggetti e volti umani, il riconoscimento vocale, la traduzione linguistica, i giochi (scacchi, ecc.), la guida autonoma di veicoli, il monitoraggio dello stato dei sensori e le decisioni di manutenzione predittiva della macchina, la valutazione delle immagini radiografiche in ambito sanitario ecc. Per tali compiti specializzati, una DNN può raggiungere o addirittura superare le capacità umane.
Perché usare intelligenza artificiale ai margini
Prendiamo ad esempio un edificio moderno, che contiene molti sensori, dispositivi HVAC, ascensori, telecamere di sicurezza, ecc. collegati alla rete interna. Per motivi di sicurezza, latenza o solidità, è più appropriato eseguire attività di intelligenza artificiale localmente, ai margini della rete locale e inviare al cloud soltanto dati anonimizzati necessari per prendere decisioni globali.
Hardware ai margini
Per distribuire la DNN ai margini abbiamo bisogno di un dispositivo con sufficiente potenza di calcolo e al contempo un basso consumo energetico. Lo stato attuale della tecnologia offre una combinazione di CPU a basso consumo e acceleratore VPU (CPU x86 SBC + Intel Myriad X VPU) o CPU + acceleratore GPU (CPU ARM + GPU Nvidia).
Il modo più semplice per avviare la DNN è utilizzare il kit di sviluppo UP Squared AI Vision X, versione B. È basato su UP Square SBC con processore Intel Atom®X7-E3950 con 8 GB di RAM, 64 GB di eMMC, modulo AI Core X con Myriad X MA2485 VPU e fotocamera USB con risoluzione 1920 x 1080 e messa a fuoco manuale. Il kit è preinstallato con Ubuntu 16.04 (kernel 4.15) e OpenVINO toolkit 2018 R5.
Toolkit contiene applicazioni demo precompilate in /home/upsquared/build/intel64/Release e modelli pre-addestrati in /opt/intel/computer_vision_sdk/deployment_tools/intel_models. Per visualizzare la guida per qualsiasi applicazione demo, eseguirla nel terminale con l’opzione –h. Si consiglia di inizializzare l’ambiente OpenVINO prima di eseguire l’applicazione demo tramite il comando source /opt/intel/computer_vision_sdk/bin/setupvars.sh.
Oltre al kit di sviluppo UP Squared AI Vision X, AAEON offre anche:
1.moduli Myriad X MA2485 basati su VPU: AI Core X (mPCIe full-size, 1x Myriad X), AI Core XM 2280 (M.2 2280 tasto B+M, 2x Myriad X), AI Core XP4/XP8 (scheda PCIE [x4], 4 o 8x Myriad X);
2.Serie BOXER-8000 basata sul modulo Nvidia Jetson TX2;
3.BOXER-8320AI con processore Core i3-6100U o Celeron 3955U e due moduli AI Core X;
4.Serie Boxer-6841M con scheda madre per processore Intel di 6°/7° generazione di Core-I o Xeon per socket LGA1151 e 1 slot PCIe [x16] o 2x PCIe [x8] per GPU con consumo energetico di max. 250W.
Hardware per l’apprendimento
Per addestrare la DNN abbiamo bisogno di un’elevata potenza di calcolo. Ad esempio, nella competizione ImageNet del 2012, il team vincitore ha utilizzato la rete neurale convoluzionale AlexNet. Operazioni TFLOP 1.4 ExaFLOP = 1,4 e 6 erano necessarie per l’apprendimento. Sono stati necessari 5-6 giorni su due GPU Nvidia GTX 580, dove ognuna ha le prestazioni di calcolo 1.5 TFLOP.La tabella seguente riassume la massima potenza di picco teorica dell’hardware.
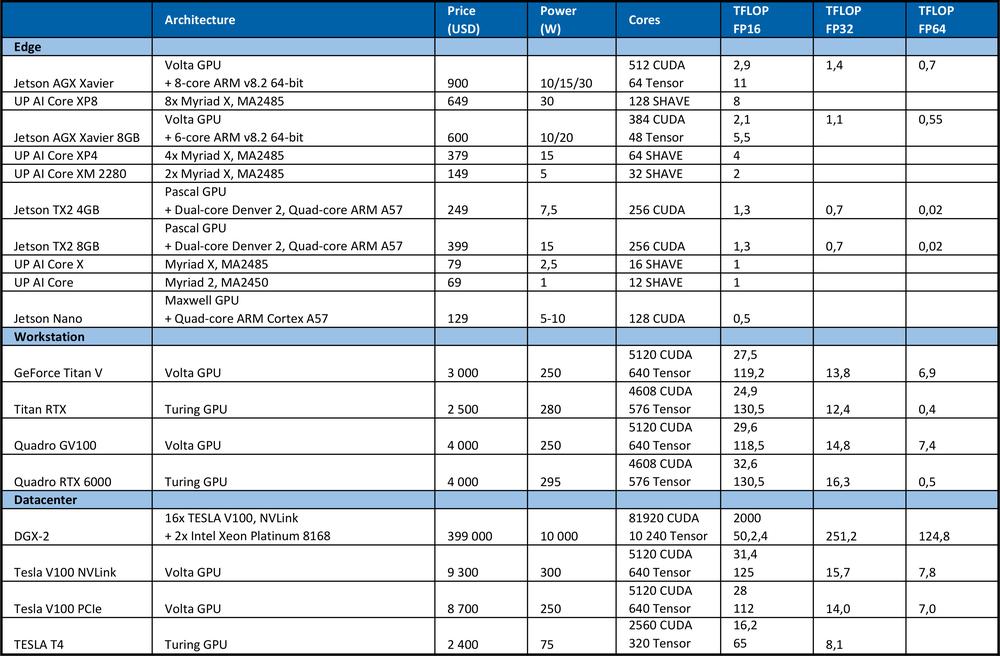
Per fare un confronto, il processore Intel Xeon Platinum 8180 di fascia alta
●ha 28 nuclei con 2 unità AVX-512 e FMA per nucleo;
●frequenza turbo AVX-512 da 2.3GHz se tutti i nuclei sono attivi;
●costa 10 000 USD;
Offre potenza di picco teorica: # di nuclei * frequenza in GHz * AVX-512 DP FLOPS / Hz # di unità AVX-512 * 2 = 2060,8 GFLOPS in doppia precisione (DP) → 4.1216 TFLOPS in singolo (32 bit).
Come si può vedere dalla tabella sopra, il GPU offre molte più prestazioni per l’apprendimento delle reti neurali. È necessario notare che il numero di operazioni al secondo non è l’unico parametro che influenza le prestazioni di apprendimento. Anche fattori quali dimensioni della RAM, velocità di trasferimento dei dati tra CPU e RAM, GPU e GPU RAM o tra GPU influenzano la velocità di apprendimento.
Software

OpenVINO
Il toolkit OpenVINO (inferenza visiva aperta e rete neurale) è un software gratuito che consente una rapida implementazione di applicazioni e soluzioni che emulano la visione umana.
Il toolkit OpenVINO toolkit:
●utilizza la CNN (rete neurale convoluzionale);
●può dividere il calcolo tra CPU Intel, GPU integrata, Intel FPGA, Intel Movidius Neural Compute Stick e acceleratori di visione con le VPU Intel Movidius Myriad;
●fornisce un’interfaccia ottimizzata per OpenCV, OpenCL e OpenVX;
●supporta i framework Caffe, TensorFlow, MXNet, ONNX, Kaldi.
TensorFlow
TensorFlow è una libreria open source per il calcolo numerico e l’apprendimento automatico. Fornisce una comoda API front-end per la creazione di applicazioni nel linguaggio di programmazione Python. Tuttavia, l’applicazione generata da TensorFlow stesso viene convertita in codice C++ ottimizzato che può essere eseguito su una varietà di piattaforme, quali CPU, GPU, computer locale, un cluster nel cloud, dispositivi integrati ai margini e simili.
Altri software utili:
Jupyter Lab / Notebook
https://jupyter.org/index.html
https://github.com/jupyter/jupyter/wiki/Jupyter-kernels
https://jupyterlab.readthedocs.io/en/stable
Keras
Pandas
MatplotLib
Numpy
Come funziona
Modello di neurone semplificato
Modello di neurone semplice: il percettrone fu descritto per la prima volta da Warren McCulloch e Walter Pitts nel 1943 e rappresenta ancora lo standard di riferimento nel campo delle reti neurali.
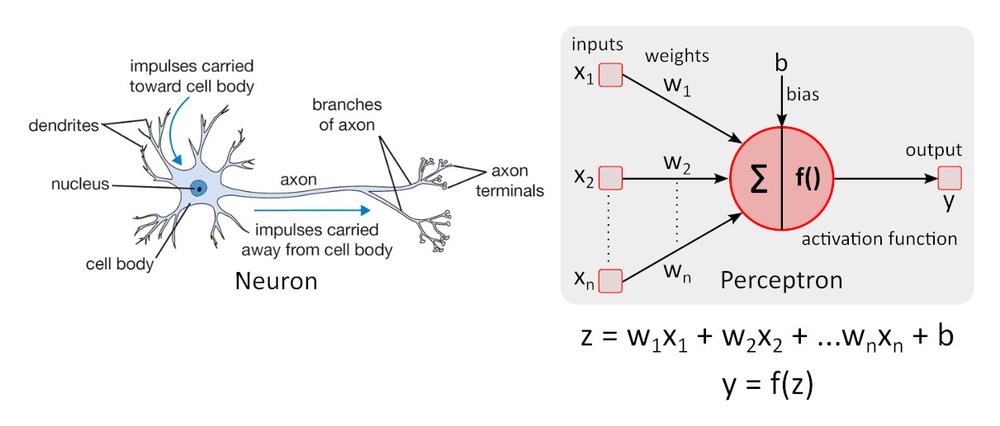
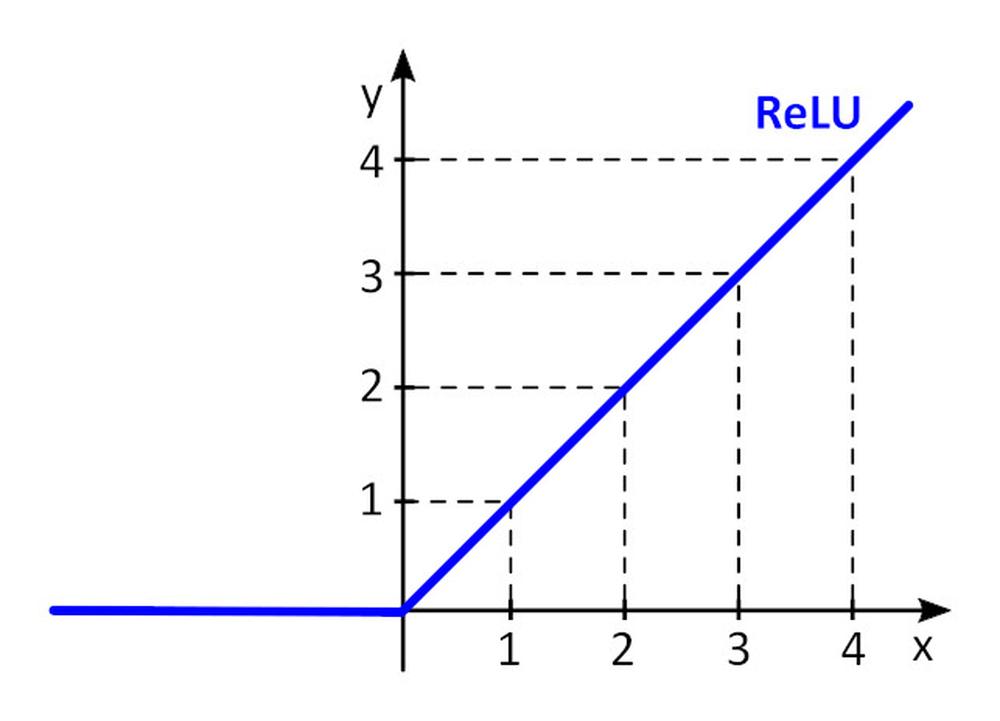
La funzione di attivazione f () aggiunge non linearità al percettrone. Senza la funzione di attivazione non lineare nella rete neurale (NN) dei percettroni, indipendentemente dalla quantità di strati, si comporterebbe proprio come un percettrone a strato singolo, perché la somma di questi strati risulterebbe solo in un’altra funzione lineare. La funzione di attivazione più utilizzata è l’unità lineare rettificata, ReLU.
y = f(x) = max (0, x), for x < = 0, y = 0, for x ≥ 0, y=x

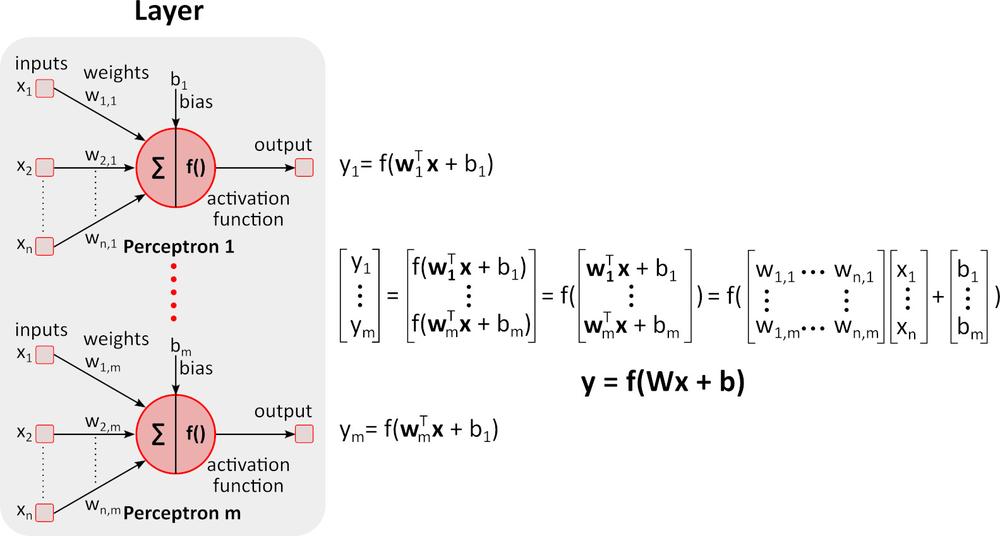
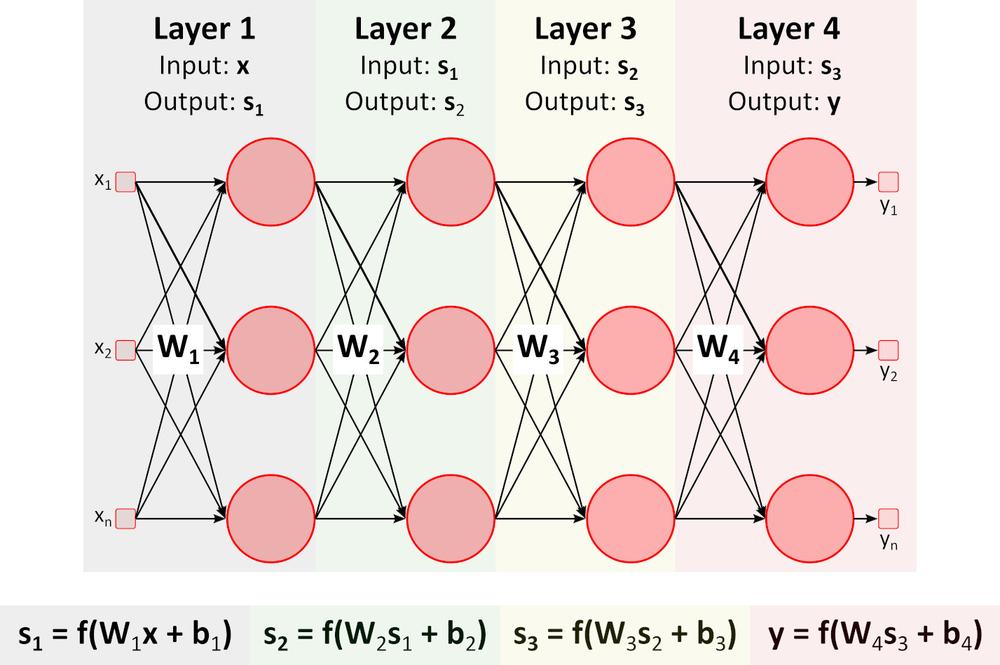
Inferenza (percorso ascendente)
L’immagine sopra mostra la rete neurale profonda (DNN) perché contiene più livelli tra quelli di input e output. Come si può notare, la DNN richiede moltiplicazioni e aggiunte di matrici. L’hardware speciale ottimizzato per questo compito, come la GPU (unità di elaborazione grafica) e la VPU (unità di elaborazione della visione), è molto più veloce della CPU per uso generale (unità di elaborazione centrale, processore) e ha un consumo energetico inferiore.Apprendimento (percorso discendente)
Diciamo che vogliamo insegnare alla DNN a riconoscere nell’immagine arancia, banana, mela e lampone (classi di oggetti).
1. Prepariamo molte immagini di tali frutti e le dividiamo in set di addestramento e set di convalida. Il set di addestramento contiene immagini e risultati corretti richiesti per queste immagini. La DNN avrà 4 output. Il primo output fornisce il punteggio (la probabilità) che la frutta nell’immagine sia un’arancia, il secondo fornisce lo stesso per la banana ecc.
2.Impostiamo i valori iniziali per tutti i pesi w_i e polarizzazioni b_i. Generalmente vengono utilizzati valori casuali.
3.Passiamo la prima immagine attraverso la DNN. La rete fornisce punteggi (probabilità) su ciascun output. Diciamo che la prima immagine raffigura l’arancia. Le uscite di rete possono essere y = (arancia, banana, mela, lampone) = (0,5, 0,1, 0,3, 0,1). La rete "afferma" che l’ingresso è l’arancia con probabilità di 0,5.
4.Definiamo una funzione di perdita (errore) che quantifica l’accordo tra i punteggi previsti e i punteggi corretti per ogni classe. La funzione E = 0,5*sum (e_j) ^2, dove e_j = y_j - y_real_j e j è il numero di immagini nel set di addestramento che viene spesso utilizzato. E_1_orange = 0.5*(0.5-1)^2=0.125, E_1_banana =.0.5*(0.1-0)^2 = 0.005 E_1_apple = 0.5*(0.3-0)^2 = 0.045, E_1_raspberry = 0.5*(0.1-0)^2 = 0.005 E_1 = (0.125, 0.005, 0.045, 0.005)
5.Passiamo tutte le immagini rimanenti dal set di addestramento tramite la DNN e calcoliamo il valore della funzione di perdita E (E_orange, E_banana, E_apple, E_raspberry) per l’intero set di addestramento.
6.Per modificare tutti i pesi w_i e polarizzazioni b_i per il prossimo passaggio di addestramento (epoca), è necessario conoscere l’influenza di ciascun parametro w_i e b_i sulla funzione di perdita per ogni classe. Se l’aumento del valore del parametro provoca l’aumento del valore della funzione di perdita, è necessario ridurre questo parametro e viceversa. Ma come calcolare l’aumento o la riduzione dei parametri richiesti?
Proviamo con un semplice esempio.
Abbiamo tre punti con coordinate (x, y): (1, 3), (2.5, 2), (3.5, 5). Vogliamo trovare una riga y = w.x + b per la quale la funzione di perdita E = 0,5*sum (e_j) ^2, dove e_j = y_j - y_real_j, j = 1, 2, 3 è minima. Per rendere l’attività il più semplice possibile, diciamo che w = 1.2 e dobbiamo trovare il valore ottimale solo per b. Scegliamo il valore iniziale per b = 0.
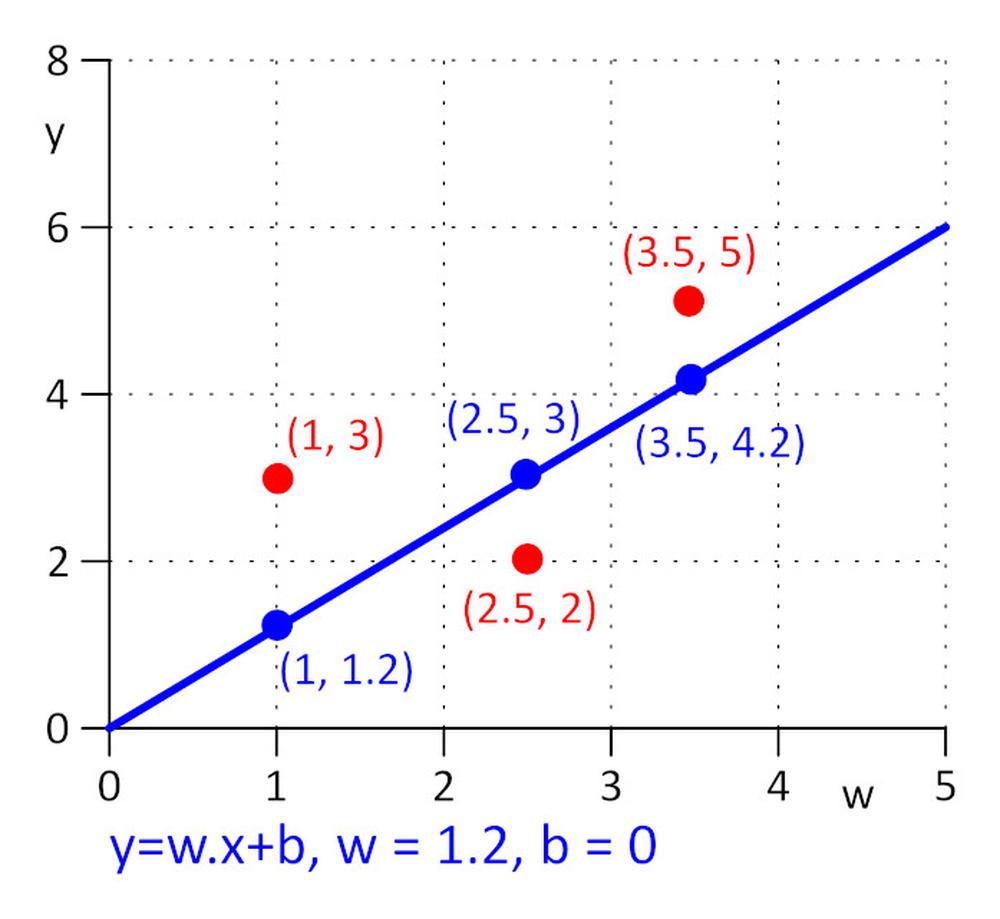
Calcoliamo la funzione di perdita: E = 0.5*sum (e_j) ^2 = 0.5*(e_1^2 + e_2^2 + e_3^2), e_1=1.2*1 + b -3, e_2 = 1.2*2.5 + b – 2, e_3 = 1.2*3.5 + b – 5.
La funzione di perdita E è semplice, possiamo trovare un minimo di E risolvendo l’equazione: ∂E/∂b = 0. È una funzione composta: per calcolare ∂E/∂b applichiamo la regola della catena.
∂E/∂b=0.5*((∂E/∂e_1)*(∂e_1/∂b) + (∂E/∂e_2)*(∂e_2/∂b) + (∂E/∂e_3)*(∂e_3/∂b)) = 0.5*(2*e_1*1 + 2*e_2*1 + 2*e_3*1) = (1.2*1 + b – 3) + (1.2*2.5 + b – 2) + (1.2*3.5 + b – 5) = 0 => b = 0.53333
In pratica, dove il numero di parametri w_i e b_i può raggiungere un milione o più, non è pratico risolvere direttamente l’equazione ∂E/∂b_i = 0 e ∂E/∂b_i = 0. Al suo posto si utilizza invece l’algoritmo iterativo.
Abbiamo iniziato con b = 0, il valore successivo sarà b_1 = b_0 – η*∂E/∂b, dove η è il tasso di apprendimento (iperparametro) e -η*∂E/∂b è la dimensione del passo. Smettiamo di apprendere quando la dimensione del passo raggiunge la soglia definita, in pratica 0,001 o inferiore. Per η = 0.3, b_1 = 0.48, b_2 = 0.528, b_3 = 0.5328 e b_4 = 0.53328 e b_5 = 0.5533328. Dopo 5 iterazioni la dimensione del passo è scesa a 4.8e-5. Qui termina l’apprendimento. Il valore di b ottenuto da questo algoritmo è praticamente uguale al valore ottenuto risolvendo l’equazione ∂E/∂b =0.
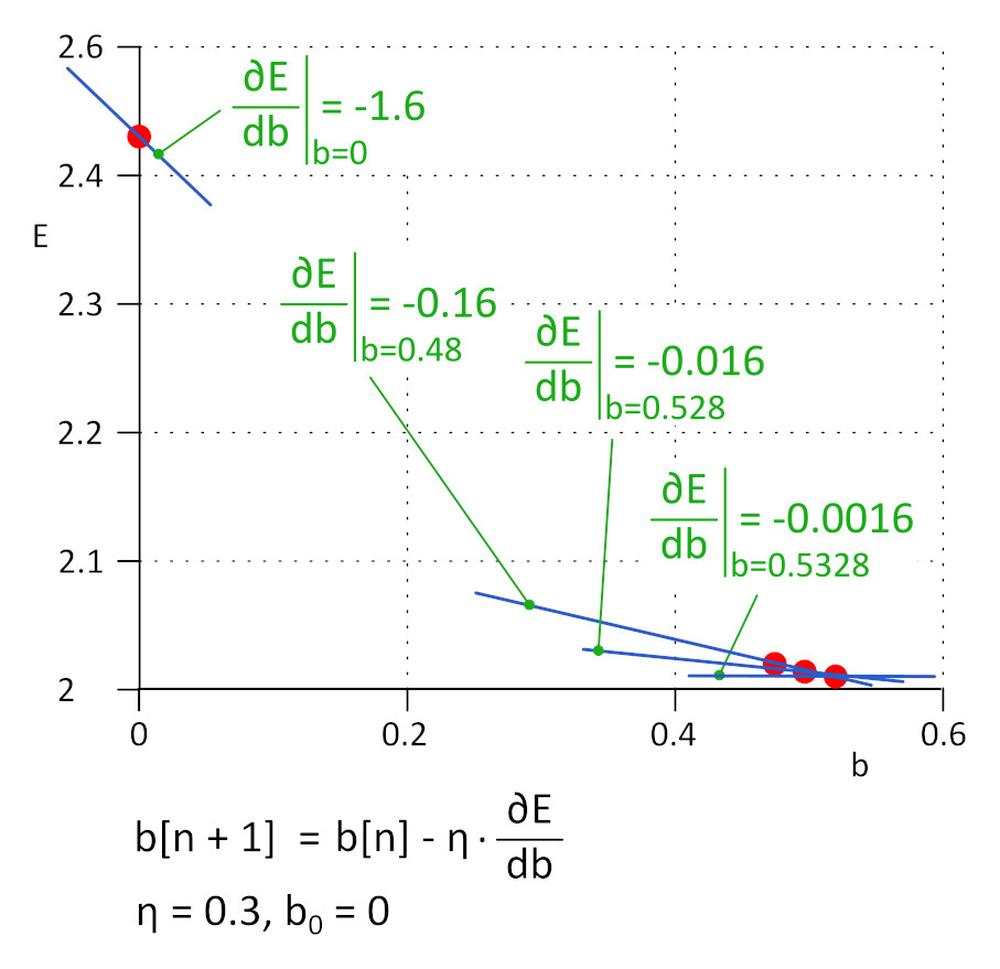
Questo metodo è chiamato discesa del gradiente.
Il tasso di apprendimento è un importante iperparametro. Se è troppo piccolo, sono necessari molti passaggi per trovare la funzione di perdita minima; se è alto, l’algoritmo può fallire. In pratica, vengono utilizzate varianti migliorate di algoritmo quali Adam.
7.Ripetiamo i passaggi 5 e 6 fino a quando il valore della funzione di perdita non diminuisce al valore richiesto.
8.Trasmettiamo il set di convalida tramite la DNN addestrata e valutiamo l’accuratezza.
Al momento, l’apprendimento della DNN è un lavoro altamente sperimentale. Sono note molte architetture DNN, ognuna delle quali è adatta per una particolare gamma di attività. Ogni architettura DNN ha il proprio set di iperparametri che ne influenzano il comportamento. Con un po’ di pazienza il risultato arriverà presto.
Per ulteriori informazioni sui prodotti AAEON, non esitare a contattarci all’indirizzo aaeon@soselectronic.com
Ti piacciono i nostri articoli? Non perderne nemmeno uno! Non devi preoccuparti di nulla, organizzeremo la consegna per te.













